FAQ по RSS-фідам
Які вимоги до сторінки відстежування?
Зазначена сторінка відстежування має бути загальнодоступною, містити розпізнаваний вихідний код HTML і містити посилання на сторінки внутрішніх публікацій (якщо вказано URL-шаблон пошуку – відповідні посилання).
Як працює автоматичне створення каналу?
Стрічка створюється на основі вмісту, отриманого з веб-сайту. Джерелом даних може бути розмітка статей Schema.org: Article, NewsArticle, BlogPosting, LiveBlogPosting і метадані Open Graph, а також стандартні теги документів HTML.
Якщо на веб-сайті не виявлено структурованих даних, Mysitemapgenerator намагається автоматично визначити вміст публікацій за допомогою алгоритму розпізнавання на основі ШІ. Але для досягнення кращих результатів ми рекомендуємо використовувати розмітку Schema.org на вашому веб-сайті.
Якщо на веб-сайті не виявлено структурованих даних, Mysitemapgenerator намагається автоматично визначити вміст публікацій за допомогою алгоритму розпізнавання на основі ШІ. Але для досягнення кращих результатів ми рекомендуємо використовувати розмітку Schema.org на вашому веб-сайті.
Як MySitemapGenerator знаходить і розуміє статті, опубліковані на веб-сайті
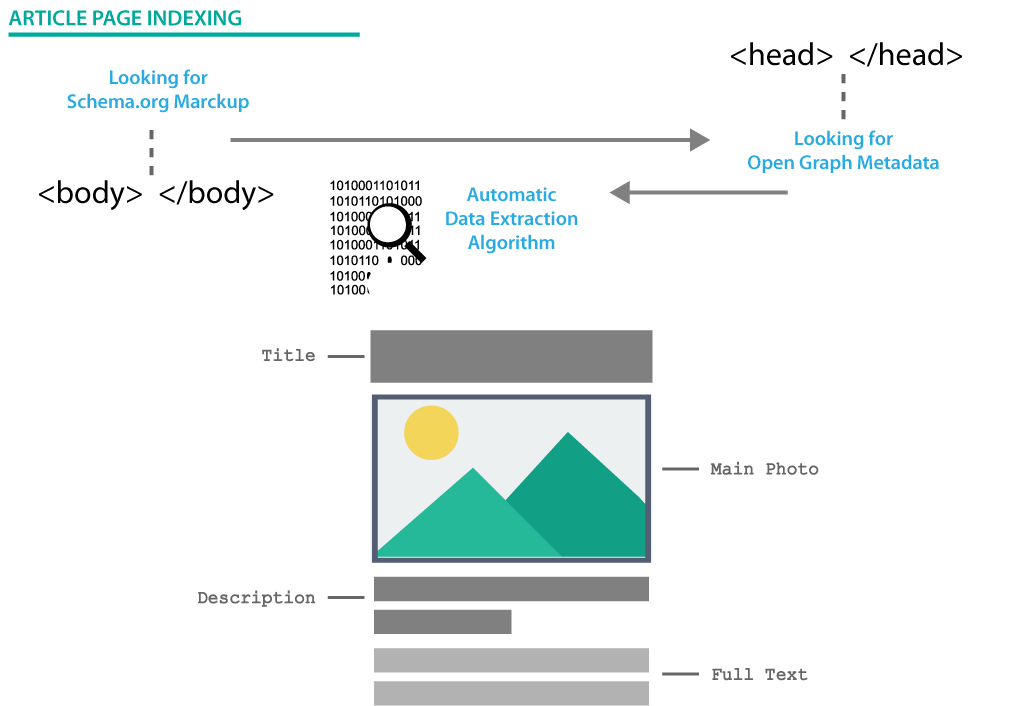
What types of structured data are retrieved by MySitemapGenerator
Supported Schema.org markup types: Article, NewsArticle, BlogPosting, LiveBlogPosting:
Schema.org markup sample for news article:
Schema.org markup sample for any article:
Open Graph metadata (Supported type: Article):
Open Graph markup example:
An example of pure HTML markup:
- headline - Article title.
- description - Article short description.
- articleBody - Article text.
- image - The URL of an image resource .
- category - Article category.
- datePublished - Date.
Schema.org markup sample for news article:
<div vocab="http://schema.org/" typeof="NewsArticle">
...
<h1 property="headline">Article title</h1>
<span property="description">Article short description</span>
<img itemprop="image" src="http://youwebsiteurl/pictures/thumbnail.jpg" />
<span itemprop="datePublished" content="1998-09-04T19:25:33+00:00">Today, 19:25</span>
...
<div property="articleBody">
<p>Article full contents</p>
...
</div>
...
</div>Schema.org markup sample for any article:
<div itemscope itemtype="http://schema.org/Article"> <h1 itemprop="headline">Article title</h1> <div itemprop="description">Article short description</div> <div itemprop="articleBody"> <p>Article full contents</p> ... </div> </div>
Open Graph metadata (Supported type: Article):
- og:title — Article title.
- og:description — Article short description.
- og:image — The URL of an image resource.
- article:published_time - Date.
Open Graph markup example:
<meta property="og:type" content="article" />
<meta property="og:title" content="Article title" />
<meta property="og:description" content="Article short description" />
<meta property="og:image" content="http://youwebsiteurl/pictures/thumbnail.jpg" />
<meta property="article:published_time" content="1998-09-04T19:25:33+00:00" />An example of pure HTML markup:
...
<head>
...
<title>Article title</title>
<meta name="description" content="Article short description" />
...
</head>
<body>
...
<article>
<p>Article full contents</p>
...
</article>
...
</body>
...How is the formation of full-text RSS in the format for export to Google Publisher Center?
In addition to standard RSS 2.0 elements, the special element "content:encoded" is required to export data to Google Publisher Center, which contains the full contents of the publication:
To include the full content of publications, the feed must use the additional namespace:
HTML-formatted text should be wrapped by CDATA section.
Our crawler extracts the full text of publications on web pages using an AI algorithm, as well as on pages marked up with Schema.org markup (supported types: Article, NewsArticle, BlogPosting, LiveBlogPosting).
<content:encoded>Full contents of the publication</content:encoded>To include the full content of publications, the feed must use the additional namespace:
xmlns:content="http://purl.org/rss/1.0/modules/content/"Our crawler extracts the full text of publications on web pages using an AI algorithm, as well as on pages marked up with Schema.org markup (supported types: Article, NewsArticle, BlogPosting, LiveBlogPosting).
How occurs RSS forming in the format of data export to Yandex News?
Along with standard RSS 2.0 elements, in order to export data into Yandex a special elemnt "yandex-fulltext" is needed, which should contain full contents of the publication:
To include the full content of publications, the feed must use the additional namespace:
HTML-formatted text should be wrapped by CDATA section.
Full text should not contain the name of the source and date/time of the publication, and contact information or any other information, which is repeated in every publication.
<yandex-fulltext>Full contents of the publication</yandex-fulltext>To include the full content of publications, the feed must use the additional namespace:
xmlns:yandex="http://news.yandex.ru"Full text should not contain the name of the source and date/time of the publication, and contact information or any other information, which is repeated in every publication.
How do you let visitors know you have an RSS feed?
The easiest way is to create a link to your RSS feed and place it on your website. By clicking on it, visitors will be able to subscribe to updates through their RSS reader.
Another way is to add a following meta tag to the <head> section of the HTML-page:
* "Feed Title" - RSS feed title,
** "URL" - Destination feed URL.
When your site contains this meta tag, some browsers add a special icon, which is a link to your RSS feed, located in the right corner of the address bar.
<a href="URL**">Subscribe via RSS</a>
Another way is to add a following meta tag to the <head> section of the HTML-page:
<head> … <link rel="alternate" type="application/rss+xml" title="Feed Title*" href="URL**"> … </head>
* "Feed Title" - RSS feed title,
** "URL" - Destination feed URL.
When your site contains this meta tag, some browsers add a special icon, which is a link to your RSS feed, located in the right corner of the address bar.