Creating RSS Feeds
How does MySitemapGenerator find and understand published articles?
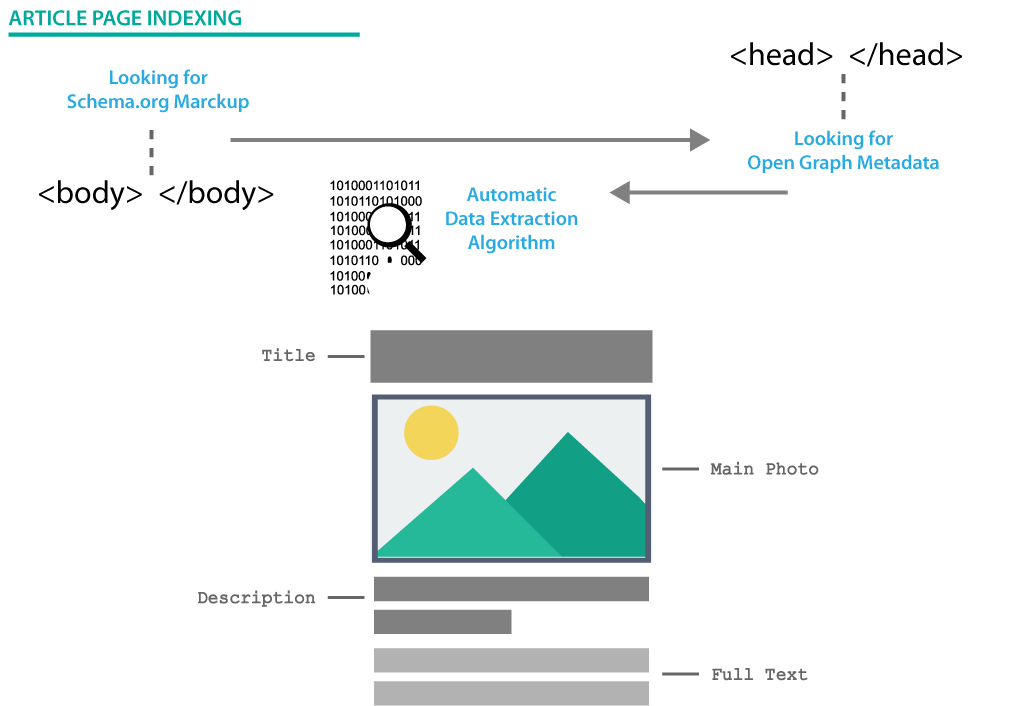
The RSS feed is generated based on content retrieved from the website. Data sources may include Schema.org markup and Open Graph Article metadata, along with standard HTML document tags and available page content.
MySitemapGenerator supports the following Schema.org types:
- Article
- NewsArticle
- BlogPosting
- LiveBlogPosting
Additionally, MySitemapGenerator supports Open Graph metadata for the Article type.
If no structured data is detected, MySitemapGenerator attempts to automatically identify publication content using an AI-based extraction algorithm.
Can’t find the answers you’re looking for? We’re here to help.
Contact support